The COVID19 vaccines (plural!) are rolling out around the world, and about 4 weeks ago in late Feb, Australians got their first vaccine jab. It’s a pretty massive relief that these vaccines (plural!!!) are rolling out so soon.
The ABC helps answer, “When will you get the COVID-19 vaccine?", which is super cool! The Australian government reckons we’ll be vaccinated at a good percentage (80%?) by sometime later in the year - I forget exactly when they said, but let’s say about October.
Now, I’m not sure how to imagine how this all takes place, but one thing I thought might be an interesting proxy is using the number of COVID19 tests that we can conduct in a day in Australia to proxy in for the number of vaccinations we can do.
Now, sure, getting a test isn’t the same as getting a vaccine, but there are similar PPE controls in place, waiting in queue, and getting swabbed takes about as long as a jab, and I figured it might tell us something.
Fortunately the data is very accessible so it’s a question that we can answer with R, some web scraping, some data wrangling, and some graphs.
So the question I’m focusing on in this blog post is:
“Based on the COVID19 tests that Australia can perform each day, how long will it take to get to 80% of Australians vaccinated?”.
To do this we’ll recycle some of the code from my previous blog post on exploring covid numbers in Australia - I skim over some of the repeated parts of code in this post, but I do provide a full explanation at the previously linked blog post. The data is kindly sourced from covidliveau.
First, we load up the packages we need:
library(tidyverse)
#> ── Attaching packages ───────────────────────────── tidyverse 1.3.0 ──
#> ✔ ggplot2 3.3.3 ✔ purrr 0.3.4
#> ✔ tibble 3.1.0 ✔ dplyr 1.0.5
#> ✔ tidyr 1.1.3 ✔ stringr 1.4.0
#> ✔ readr 1.4.0 ✔ forcats 0.5.1
#> ── Conflicts ──────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
library(polite)
library(rvest)
#>
#> Attaching package: 'rvest'
#> The following object is masked from 'package:readr':
#>
#> guess_encoding
library(htmltools)
library(scales)
#>
#> Attaching package: 'scales'
#> The following object is masked from 'package:purrr':
#>
#> discard
#> The following object is masked from 'package:readr':
#>
#> col_factortidyversefor data wrangling and plotting and magicpolite,rvest,htmltoolsfor web scrapingscalesfor making nicer plot scales and stuff
We scrape the data for tests in Australia, and extract the table
aus_test_url <- "https://covidlive.com.au/report/daily-tests/aus"
aus_test_data_raw <- bow(aus_test_url) %>%
scrape() %>%
html_table() %>%
purrr::pluck(2) %>%
as_tibble()
aus_test_data_raw
#> # A tibble: 386 x 4
#> DATE TESTS VAR NET
#> <chr> <chr> <lgl> <chr>
#> 1 21 Mar 21 15,186,991 NA 34,669
#> 2 20 Mar 21 15,152,322 NA 36,037
#> 3 19 Mar 21 15,116,285 NA 44,082
#> 4 18 Mar 21 15,072,203 NA 50,496
#> 5 17 Mar 21 15,021,707 NA 54,260
#> 6 16 Mar 21 14,967,447 NA 33,843
#> 7 15 Mar 21 14,933,604 NA 32,312
#> 8 14 Mar 21 14,901,292 NA 29,392
#> 9 13 Mar 21 14,871,900 NA 36,989
#> 10 12 Mar 21 14,834,911 NA 45,015
#> # … with 376 more rowsWe then clean up the dates and numbers, defining a little function, strp_date, to present the dates nicely.
strp_date <- function(x) as.Date(strptime(x, format = "%d %b"))
aus_tests <- aus_test_data_raw %>%
mutate(DATE = strp_date(DATE),
TESTS = parse_number(TESTS),
NET = parse_number(NET)) %>%
janitor::clean_names() %>%
rename(daily_tests = net)
#> Warning: 29 parsing failures.
#> row col expected actual
#> 358 -- a number -
#> 359 -- a number -
#> 360 -- a number -
#> 361 -- a number -
#> 362 -- a number -
#> ... ... ........ ......
#> See problems(...) for more details.
aus_tests
#> # A tibble: 386 x 4
#> date tests var daily_tests
#> <date> <dbl> <lgl> <dbl>
#> 1 2021-03-21 15186991 NA 34669
#> 2 2021-03-20 15152322 NA 36037
#> 3 2021-03-19 15116285 NA 44082
#> 4 2021-03-18 15072203 NA 50496
#> 5 2021-03-17 15021707 NA 54260
#> 6 2021-03-16 14967447 NA 33843
#> 7 2021-03-15 14933604 NA 32312
#> 8 2021-03-14 14901292 NA 29392
#> 9 2021-03-13 14871900 NA 36989
#> 10 2021-03-12 14834911 NA 45015
#> # … with 376 more rowsWe get a sense of the distribution of tests by ploting the number of daily tests in Australia as a boxplot.
This extra line of code improves how big numbers are presented: scale_x_continuous(labels = label_number(big.mark = ",")), turning 100000 into 100,000. Perhaps not a big deal, but I think it helps.
ggplot(aus_tests,
aes(x = daily_tests)) +
geom_boxplot() +
scale_x_continuous(labels = label_number(big.mark = ","))
#> Warning: Removed 29 rows containing non-finite values (stat_boxplot).
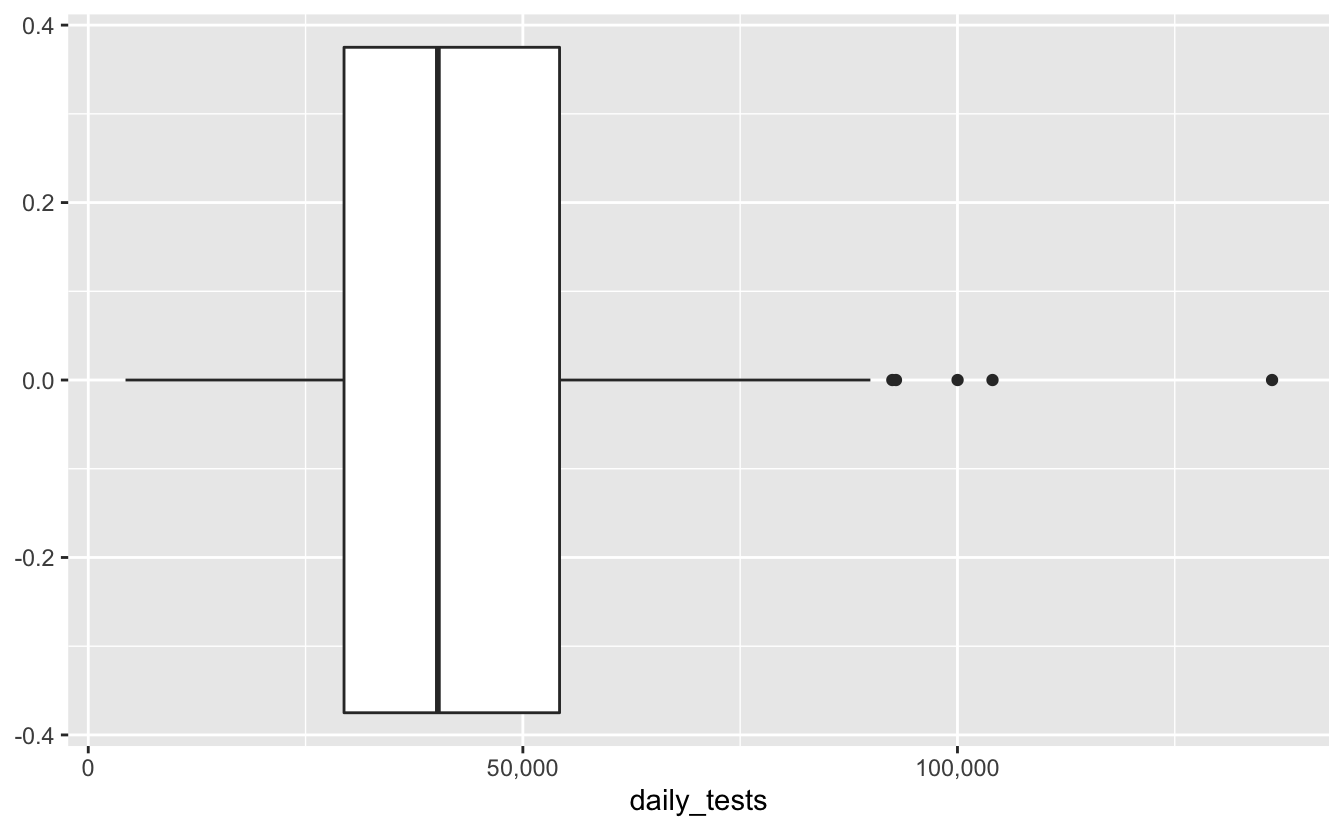
We learn most of the data is around 25-55K tests per day, give or take, and there were some extreme days where we tested over 150K! Not bad, not bad.
Another way to present the same data is to plot is as a density, along with a rug plot to show the data frequency.
gg_cov_dens <- ggplot(aus_tests,
aes(x = daily_tests)) +
geom_density() +
geom_rug(alpha = 0.2) +
scale_x_continuous(labels = label_number(big.mark = ","))
gg_cov_dens
#> Warning: Removed 29 rows containing non-finite values (stat_density).
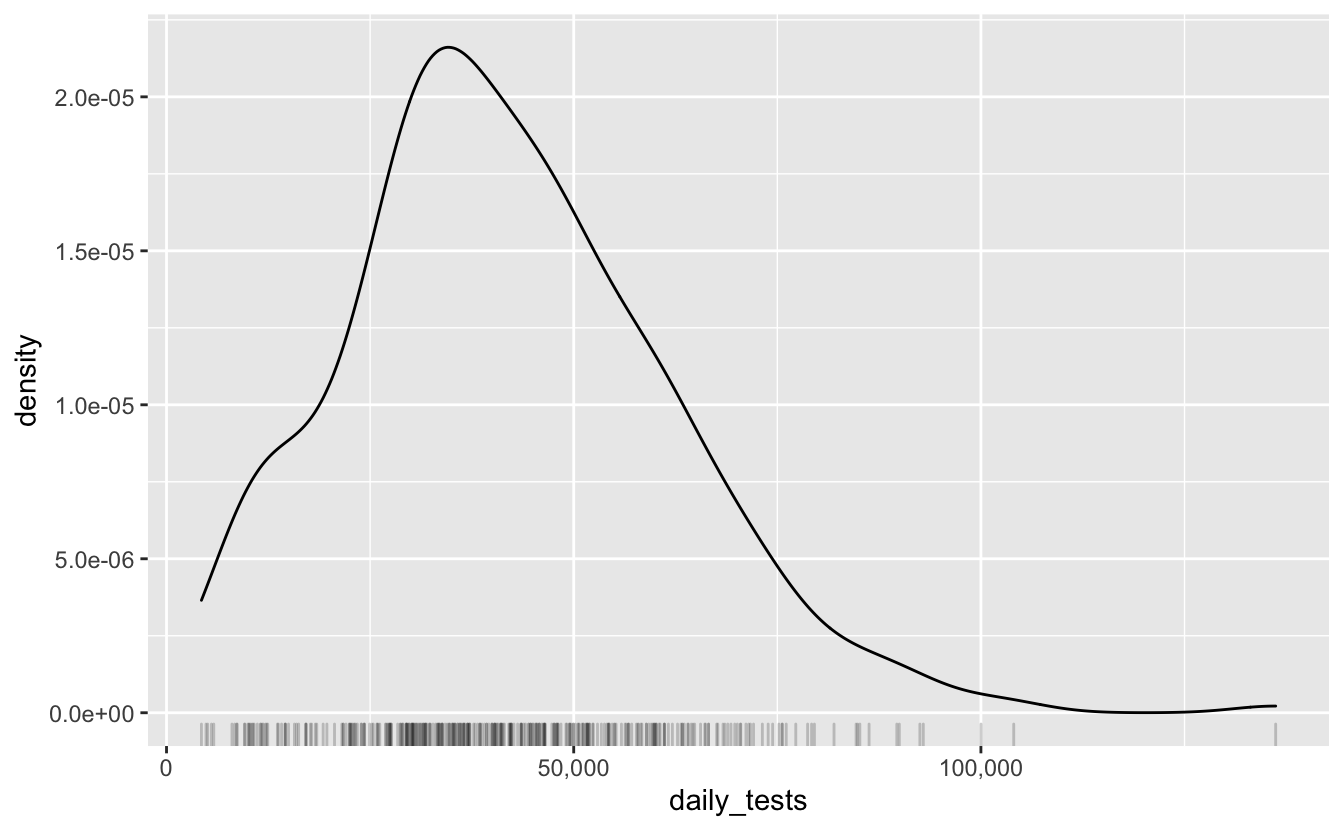
This is pretty much a similar presentation of the previous plot, it’s fun to look at, plus rug plots are great. If we’re interested in what kind of distribution this follows, we can overlay a normal curve over the top with geom_function, adding in the estimated mean and standard deviation
tests_mean <- mean(aus_tests$daily_tests, na.rm = TRUE)
tests_sd <- sd(aus_tests$daily_tests, na.rm = TRUE)
gg_cov_dens +
geom_function(fun = dnorm,
args = list(mean = tests_mean, sd = tests_sd),
colour = "orange")
#> Warning: Removed 29 rows containing non-finite values (stat_density).
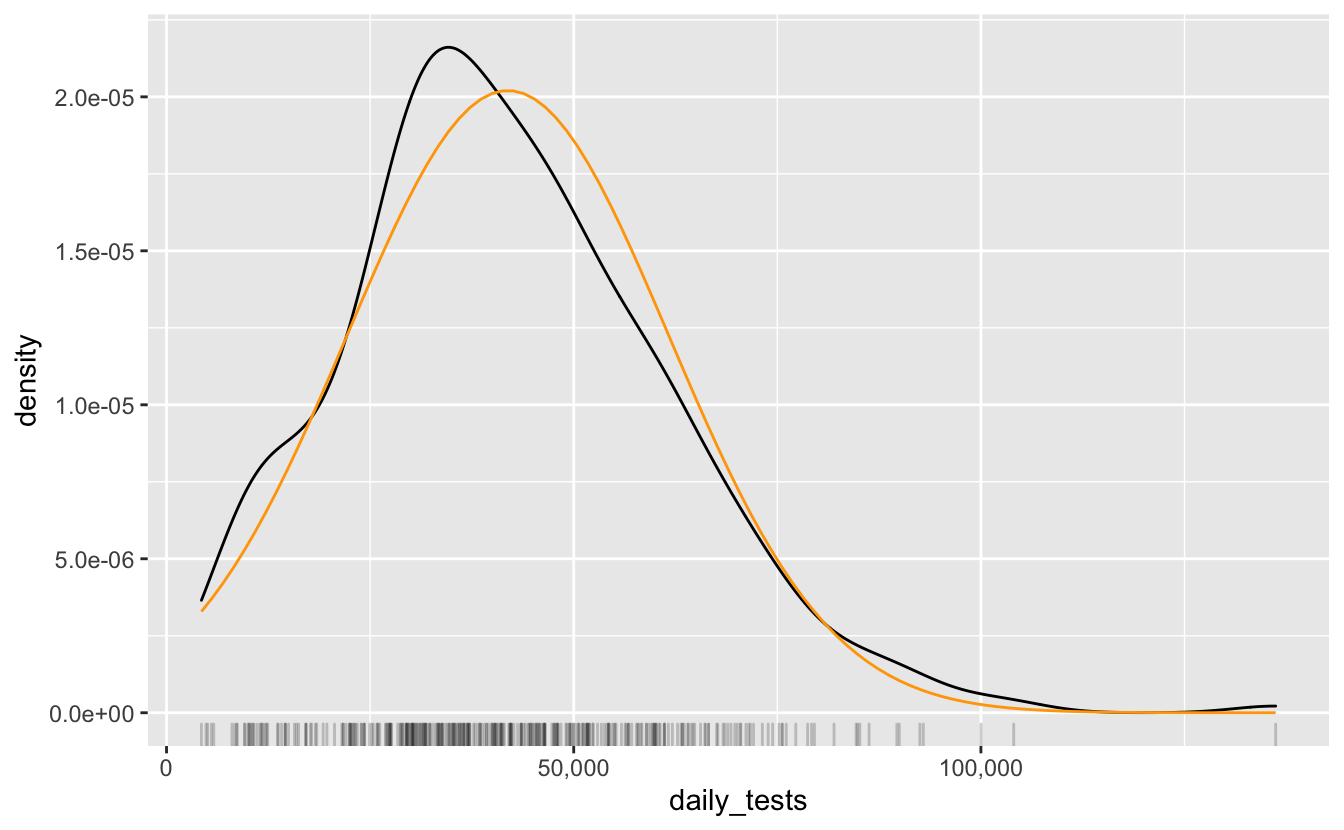
It looks somewhat normal, but it’s a bit more peaky to the left. So, if you needed to assign this a distribution, maybe representing this as a normal isn’t the best, or at least we could understand where it isn’t representing the data.
Back on task
OK so what were we doing? Back to the question:
“Based on the COVID19 tests that Australia can perform each day, how long will it take to get to 80% of Australians vaccinated?”.
Let’s calculate the maximum number of tests, and define 80% of Australia’s population.
max_tests <- max(aus_tests$daily_tests, na.rm = TRUE)
oz_pop_80_pct <- 0.8 * 25693059With this new information we then create a new table with a column of the percentage of maximum tests. We want to create a 100 row table, where each row is a percentage of the maximum tests. We can then calculate the number of days until Australia reaches 80% vaccination by dividing the number of 80% of the population bt the propotion of max tests.
covid_days_until_vac <- tibble(pct_of_max_tests = (1:100)/100,
max_tests = max_tests,
prop_of_max_tests = max_tests * pct_of_max_tests,
days_until_80_pct_aus_pop_vac = oz_pop_80_pct / prop_of_max_tests)
covid_days_until_vac
#> # A tibble: 100 x 4
#> pct_of_max_tests max_tests prop_of_max_tests days_until_80_pct_aus_pop_vac
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.01 136194 1362. 15092.
#> 2 0.02 136194 2724. 7546.
#> 3 0.03 136194 4086. 5031.
#> 4 0.04 136194 5448. 3773.
#> 5 0.05 136194 6810. 3018.
#> 6 0.06 136194 8172. 2515.
#> 7 0.07 136194 9534. 2156.
#> 8 0.08 136194 10896. 1887.
#> 9 0.09 136194 12257. 1677.
#> 10 0.1 136194 13619. 1509.
#> # … with 90 more rowsThen we can plot this!
ggplot(covid_days_until_vac,
aes(x = days_until_80_pct_aus_pop_vac,
y = pct_of_max_tests)) +
geom_line()
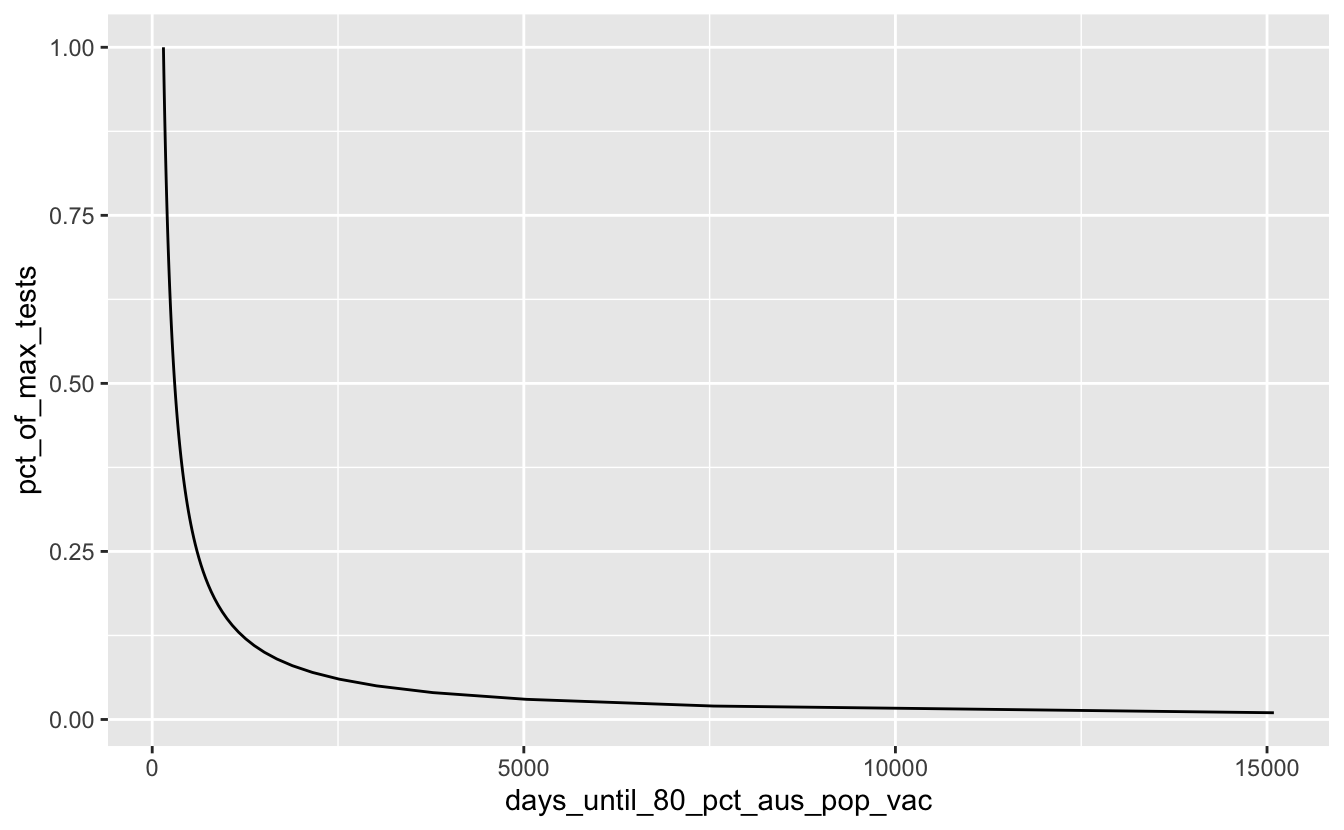
Ooof. Ok, so let’s assume that we will do better than 25% of our maximum tests by filtering that out:
covid_days_until_vac %>%
filter(pct_of_max_tests >= 0.25) %>%
ggplot(aes(x = days_until_80_pct_aus_pop_vac,
y = pct_of_max_tests)) +
geom_line()
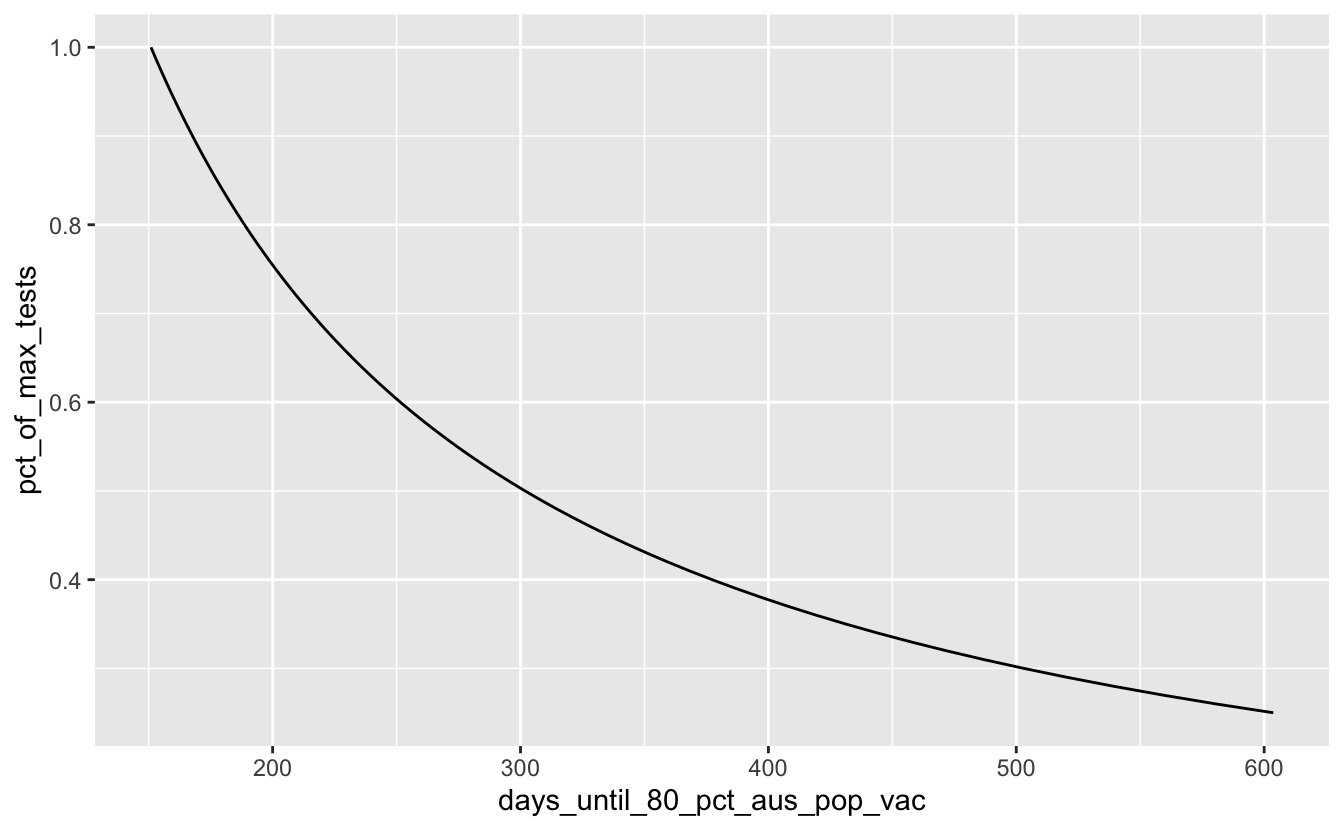
Hmmm, OK so if we want to do it within 1 year from now, looks like we’d need to do over 50% of our tests per day?
covid_days_until_vac %>%
filter(pct_of_max_tests >= 0.50) %>%
ggplot(aes(x = days_until_80_pct_aus_pop_vac,
y = pct_of_max_tests)) +
geom_line()
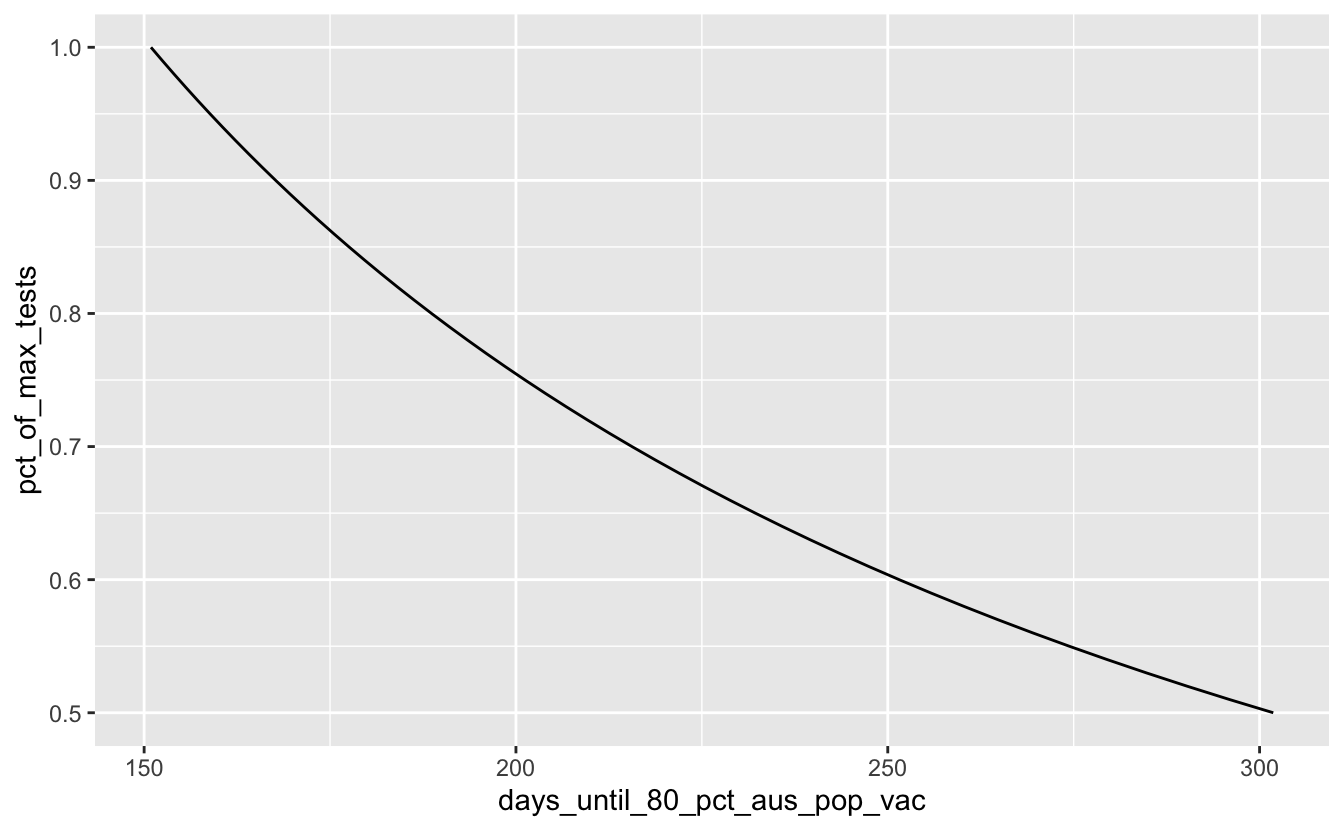
And how many tests is that now? We can change the y axis to proportion of max tests.
gg_covid_50pct_days <-
covid_days_until_vac %>%
filter(pct_of_max_tests >= 0.50) %>%
ggplot(aes(x = days_until_80_pct_aus_pop_vac,
y = prop_of_max_tests)) +
geom_line() +
scale_y_continuous(labels = label_number(big.mark = ","))
gg_covid_50pct_days
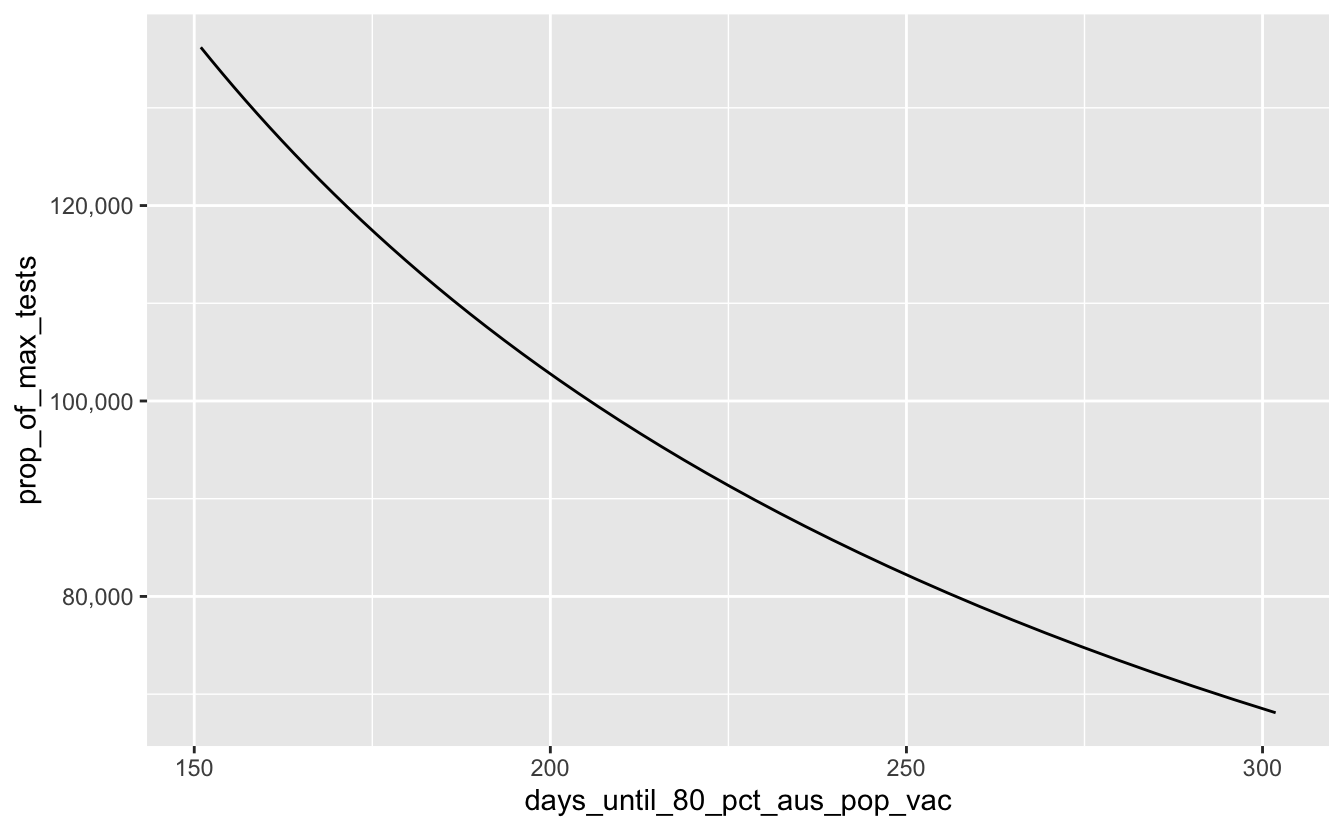
Let’s say we want to be done by October 31, that is currently how many days away? We can use lubridate to work that out:
library(lubridate)
#>
#> Attaching package: 'lubridate'
#> The following objects are masked from 'package:base':
#>
#> date, intersect, setdiff, union
n_days_until_vac <- ymd("2021-10-31") - today()
n_days_until_vac
#> Time difference of 224 daysSo that’s 224 days.
gg_covid_50pct_days +
geom_vline(xintercept = n_days_until_vac,
colour = "red",
lty = 2)
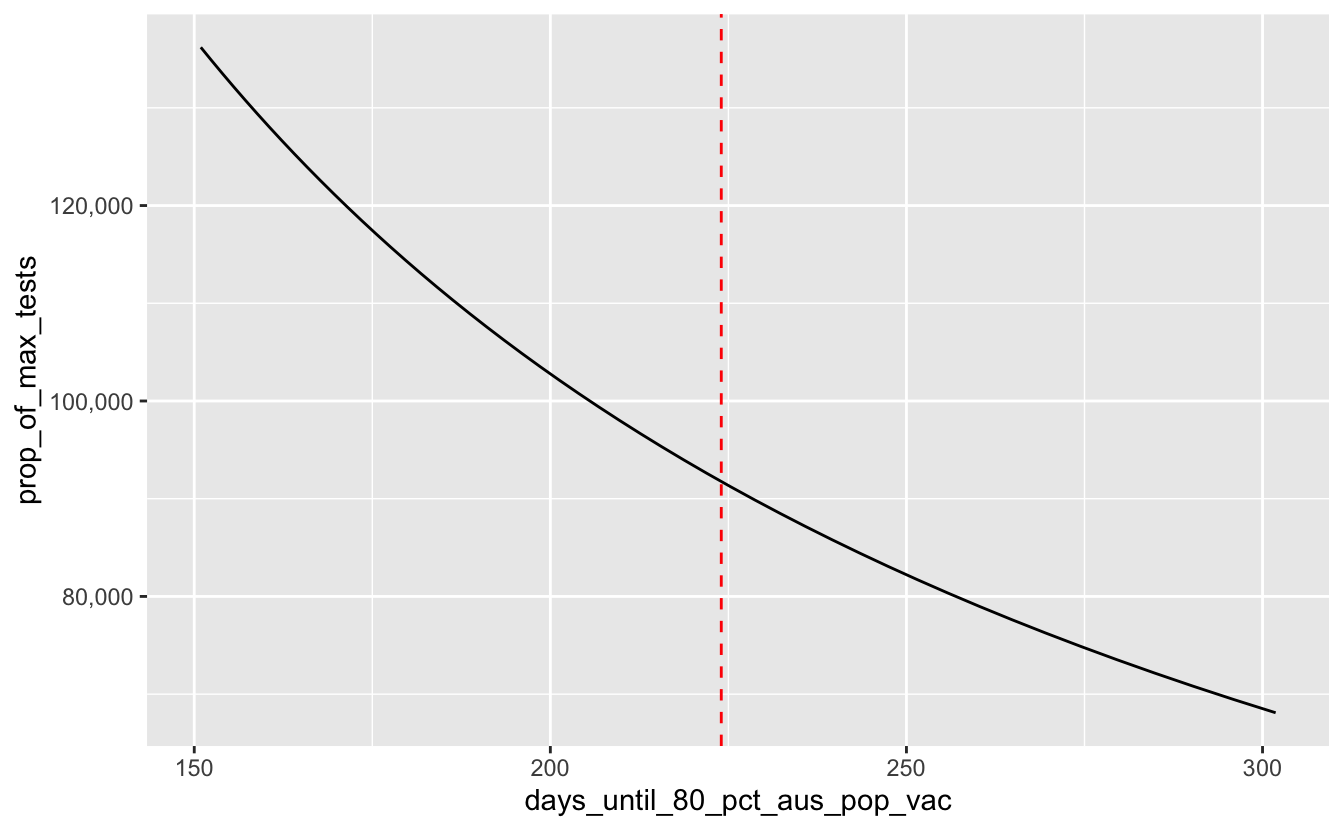
And that means we need about this many tests per day:
n_tests_per_day_needed <-
covid_days_until_vac %>%
# there is no 224 days
filter(days_until_80_pct_aus_pop_vac <= 225) %>%
slice_head(n = 1) %>%
pull(max_tests)
n_tests_per_day_needed
#> [1] 136194So we need doses per day to get there by October.
What are COVID vaccinations like currently in Australia?
And because why not, let’s look at what COVID vaccinations are currently like in Australia.
aus_vac_url <- "https://covidlive.com.au/report/daily-vaccinations/aus"
aus_test_data_raw <- bow(aus_vac_url) %>%
scrape() %>%
html_table() %>%
purrr::pluck(2) %>%
as_tibble() %>%
janitor::clean_names() %>%
mutate(date = strp_date(date)) %>%
mutate(net = stringr::str_replace_all(string = net,
pattern = "-",
replacement = "0")) %>%
mutate(across(c("cwealth", "doses", "net"), parse_number)) %>%
rename(daily_vacc = net)
aus_test_data_raw
#> # A tibble: 35 x 5
#> date cwealth doses var daily_vacc
#> <date> <dbl> <dbl> <lgl> <dbl>
#> 1 2021-03-21 50000 256782 NA 2951
#> 2 2021-03-20 50000 253831 NA 13077
#> 3 2021-03-19 50000 240754 NA 14697
#> 4 2021-03-18 50000 226057 NA 22500
#> 5 2021-03-17 45607 203557 NA 21120
#> 6 2021-03-16 42800 182437 NA 17656
#> 7 2021-03-15 39760 164781 NA 2230
#> 8 2021-03-14 39760 162551 NA 3257
#> 9 2021-03-13 38934 159294 NA 24191
#> 10 2021-03-12 30000 135103 NA 10103
#> # … with 25 more rowsggplot(aus_test_data_raw,
aes(x = date,
y = doses)) +
geom_line() +
scale_y_continuous(labels = label_number(big.mark = ","))
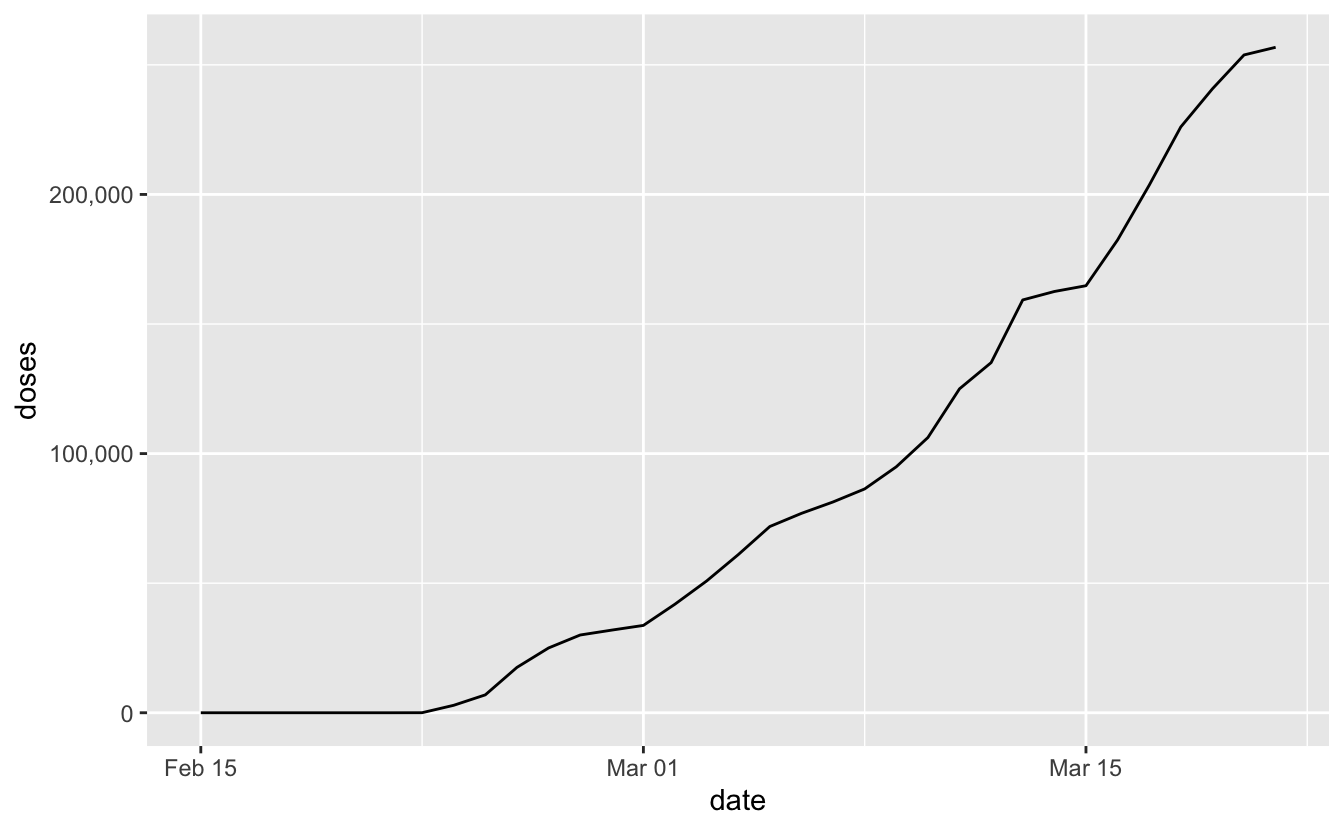
Things are just starting out here in Australia with the vaccine, but we’re doing to need to see some pretty substantial ramp ups in the future to meet a goal date of the end of October.